目录
一,关于多线程
二,重新理解进程
三,线程VS进程
四,线程周边概念
4.1 线程的数据共享
4.2 线程的优点
4.3 线程的缺点
4.4 线程异常
4.5 线程用途
五,一些问题解答
如何理解将资源分配给各个线程?
既然线程优点这么多,那么是不是线程越多越好?
如何理解我们曾经学的进程呢?
一,关于多线程
概念很多,建议耐心看完哦:
- 进程申请资源都是在地址空间上申请,可以说地址空间是进程的资源窗口。父进程创建子进程,子进程创建出来后就是两个独立的进程了,虽然子进程很多数据都是从父进程来,但是有写时拷贝,所以它们都有自己的独立的地址空间和页表,它们映射到物理内存的位置不同
- 关于线程,比较官方的说法是:线程在进程内部运行,是OS调度的最基本单位
- 我们曾经创建子进程,要创建task_struct(PCB),mm_struct(地址空间数据结构)和相应的页表建立映射,但是今天我们不这么做了,我们创建“子进程”时,只创建task_struct(PCB),不创建任何其它的地址空间和页表,所以也不会在物理内存中开辟空间给这个“子进程”,与父进程“共用同一个资源窗口”
- 然后我们多创建一些这样“只创建PCB”的子进程,然后“先描述,再组织”,将当前主进程的地址空间(资源)以一定方式划分给不同的task_struct,然后每个进程都分发一些任务让它们做,这样每个“子进程”都可以malloc申请空间,共享区共享,每个线程使用栈区的一部分,就可以让所有的“子进程”的资源都在一个地址空间里申请和运行(简单来说就是所有新创建的进程与父进程共享一个地址空间)
- 而对于CPU,它不受影响,因为CPU的等待队列里只有PCB,CPU只认PCB,所以上面的没有独立地址空间和页表的“子进程”在CPU看来是一样的
- 这样产创建进程的方式和我们以前创建进程的方式有很大不同的是,我们不再创建地址空间和页表了,只创建PCB,然后线程直接伸手向父进程要资源就可以了 --> 我们把每一个这样的子进程的PCB称之为线程,线程可以让每个线程对应地函数由一个一个顺序执行编程并发执行
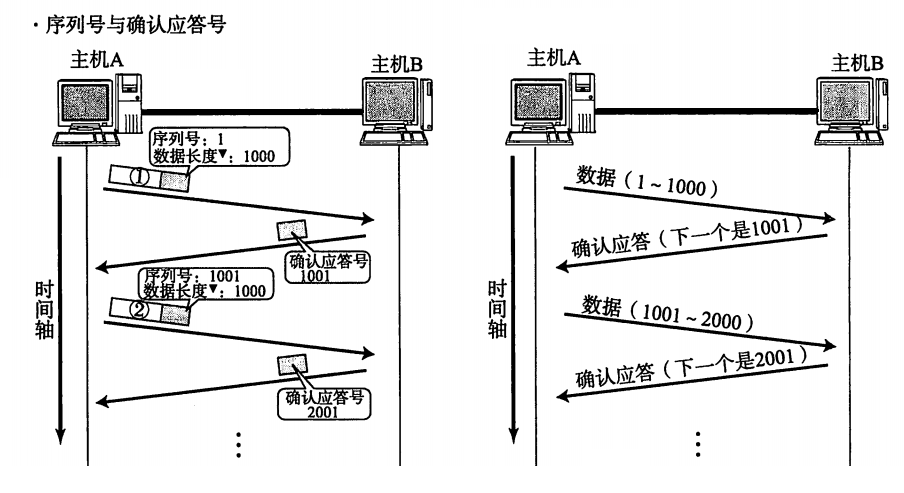
下面用图来解释:
我们曾经学的进程是下面这样的:

有了线程概念后,这个图会变成这样:

那么在Linux看来:
1,线程是在地址空间中运行的
2,每一个线程执行进程代码的一部分,所以线程的执行粒度比进程要轻很多
问题:为什么说线程在进程的地址空间中运行呢?
解答: 任何执行流要运作,必须要有资源。目前我们可以把这个“资源”简单理解为“代码”,你要想运行一个进程,那么首先得写代码,对吧
二,重新理解进程
有了线程的概念,再加上我们前面的进程的知识,下面用红色框框框起来的部分,这个整体我们叫做“轻量级进程”,如下图:

- 所以前面说的“线程在进程内运行”,我们理解为线程在进程的地址空间中运行,而对于“是OS调度的基本单位”,我们可以理解为CPU只有调度执行流的概念,也就是CPU不关心执行流是线程还是进程,只关心PCB(这是Linux系统特有的实现线程的方案),这点和Tcp协议“面向字节流”的概念很类似
- 许多教材说的线程的概念:线程比进程的执行力度更细,所需资源更少,调度轻量化成本更低。这只是线程的优点,因为不同的OS对于线程有着不同的实现方案,只要满足教材里说的,都是线程
- 所以Linux与其它OS相比,Linux没有为线程专门设计数据结构,(Windows有),线程在概念上和进程是高度重合的,OS中有大量进程那么也就会有大量线程,这就代表线程也要和进程一样“先描述,再组织”,所以OS不得不创建线程的数据结构来管理线程
- 但是,如果线程也要创建数据结构,那么实现起来会非常非常非常复杂,struct_tcb; thread_ctrl_block。但是Windows就这么干了,所以我们很佩服也很同情开发Windows的程序员们,因为太复杂了
- 但是Linux系统设计者没有这么做,Linux设计者用前面我们说的,直接用PCB代替线程的结构体巧妙地实现了线程地功能,也就是“用PCB模拟线程”,最简单直接地体现就是:服务器绝大多数都是Linux操作系统,所以Linux系统一开机一年甚至几年都可以不关机,Windows不敢。
三,线程VS进程
进程是承担分配系统资源的基本实体,线程是调度的基本单位
前面说过,线程在进程内部运行,是操作系统调度的基本单位,后面又补充道,线程其实是在进程的地址空间上运行,并且线程和进程在CPU看来都是一样的,线程的执行力度比进程轻,因为线程都是执行进程代码的一部分,就好比,一个人干的工作好几个人一起干了,肯定轻松很多
问题:为什么线程切换的成本更低呢?
- 首先线程切换不同于进程切换,地址空间不需要切换,而且页表也不需要切换
- CPU内部是有L1-L3 cache缓存的,CPU读取指令时,会把指令放到cache里,下次再来时有大概念就不会再来一个加载一个来一个加载一个了,那样整机效率会变低,放到cache里的话,下次就不需要再从汇编语言加载到CPU里了,直接在CPU内部自己执行,提升效率(cache被称为“缓存的 热数据”,也就是可能会高频使用的数据)
- 简单来说,cache对内存的代码和数据,更具局部性原理,预读CPU内部,如果进程切换,cache就立即失效;新进程过来,只能重新缓存,所以线程的执行比进程快的原因主要是在这里,由于线程是在进程里地,所以线程切换的时候cache不会失效,所以线程切换效率远高于进程切换
- 所以大部分人理解的线程切换比进程快是不需要切换地址空间和页表,但这个切换的影响不大,最主要的还是后面的cache缓存的机制,线程就是巧妙地利用了缓存来提升切换效率
四,线程周边概念
4.1 线程的数据共享
线程是共享进程数据的,但也有自己的一部分数据:
- 线程ID
- 一组寄存器:存储每个线程的上下文数据
- 栈:每个线程都有自己的临时数据,需要压栈和出栈
- errno错误码:C语言提供的全局变量,线程都有自己的
- 信号屏蔽字
- 调度优先级
其中最重要的就是:①一组寄存器 ②栈,这两个最终体现的是线程的动态特性
- 一组独立的寄存器,可以体现线程是被独立调度的
- 独立的栈:能够保证线程之间的运行是不会出现执行流错乱的情况的,因为栈里存的是运行时数据,每个线程都要有自己独立的栈区
4.2 线程的优点
- 创建一个新线程的代价要比创建一个新进程小得多
- 与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多
- 线程占用的资源要比进程少很多,能充分利用多处理器的可并行数量
- 在等待慢速IO操作结束的同时,程序可执行其他的计算任务
- 计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现
- IO密集型应用,为了提高性能,将IO操作重叠,线程可以同时等待不同的IO操作
计算密集型:执行流的大部分任务,主要以计算为主。比如加密解密、大数据查找等。
IO密集型:执行流的大部分任务,主要以IO为主。比如刷磁盘、访问数据库、访问网络等。
4.3 线程的缺点
- 性能损失: 一个很少被外部事件阻塞的计算密集型线程往往无法与其他线程共享同一个处理器。如果计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的同步和调度开销,而可用的资源不变。
- 健壮性降低: 编写多线程需要更全面更深入的考虑,在一个多线程程序里,因时间分配上的细微偏差或者因共享了不该共享的变量而造成不良影响的可能性是很大的,换句话说,线程之间是缺乏保护的。
- 缺乏访问控制: 进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响。也正是因为缺乏访问控制,才有了“线程安全”这个大板块,后面会有一篇单独的文章来详细解决线程安全问题
- 编程难度提高: 编写与调试一个多线程程序比单线程程序困难得多。
4.4 线程异常
- 单个线程如果出现除零、野指针等问题导致线程崩溃,进程也会随着崩溃
- 线程是进程的执行分支,线程出异常,就类似进程出异常,进而触发信号机制,终止进程,进程终止,该进程内的所有线程也就随即退出
4.5 线程用途
- 合理的使用多线程,能提高CPU密集型程序的执行效率
- 合理的使用多线程,能提高IO密集型程序的用户体验(如生活中我们一边吃饭一边刷视频,就是多线程运行的一种表现)
五,一些问题解答
如何理解将资源分配给各个线程?
- 线程目前的分配资源的方式,本质就是划分地址空间范围,简单来说就是分配代码和数据
- 代码也有地址,并且也是虚拟地址,假设我们在C语言中定义10个函数,每个函数地址不一样,所以只需要把每个函数交给各个线程运行,就是天然地做好了地址空间的划分,这叫做线程的代码和数据分离,我们不需要做任何事
既然线程优点这么多,那么是不是线程越多越好?
不是,CPU线程的切换虽然成本很低,但不是没有成本,而且当线程太多时,计算机的效率会变低,因为会占用CPU的资源执行线程,而导致其他进程的执行速度变慢,毕竟计算机还是以进程为主的
如何理解我们曾经学的进程呢?
- 以前的概念是:内部只有一个执行流的进程,现在的概念:内部有多个执行流,以前的概念是现在概念的子集,只有一个执行流是多个执行流的特殊情况
- 操作系统以进程为单位,给我们分配资源,只是当进程创建时,只有一个执行流罢了,所以进程的概念和线程的概念高度相似,以前学的是进程的“特殊情况”,现在学的一个进程有多个执行流才是“特殊情况”
- task_struct以现在的概念来说,就是进程内部的执行流